For NEsper .NET also see Section H.11, “.NET Processing Model Introduction”.
The Esper processing model is continuous: Update listeners and/or subscribers to statements receive updated data as soon as the engine processes events for that statement, according to the statement's choice of event streams, views, filters and output rates.
As outlined in Chapter 15, API Reference the interface for listeners is com.espertech.esper.client.UpdateListener. Implementations must provide a single update method that the engine invokes when results become available:

A second, strongly-typed and native, highly-performant method of result delivery is provided: A subscriber object is a direct binding of query results to a Java object. The object, a POJO, receives statement results via method invocation. The subscriber class need not implement an interface or extend a superclass. Please see Section 15.3.3, “Setting a Subscriber Object”.
The engine provides statement results to update listeners by placing results in com.espertech.esper.client.EventBean instances. A typical listener implementation queries the EventBean instances via getter methods to obtain the statement-generated results.

The get method on the EventBean interface can be used to retrieve result columns by name. The property name supplied to the get method can also be used to query nested, indexed or array properties of object graphs as discussed in more detail in Chapter 2, Event Representations and Section 15.6, “Event and Event Type”
The getUnderlying method on the EventBean interface allows update listeners to obtain the underlying event object. For wildcard selects, the underlying event is the event object that was sent into the engine via the sendEvent method.
For joins and select clauses with expressions, the underlying object implements java.util.Map.
Tip
The engine calls application-provided update listeners and subscribers for output. These commonly encapsulate the actions to take when there is output. This design decouples EPL statements from actions and places actions outside of EPL. It allows actions to change independently from statements: A statement does not need to be updated when its associated action(s) change.
While action-taking, in respect to the code or script taking the action, is not a part of the EPL language, here are a few noteworthy points.
Through the use of EPL annotations one can attach information to EPL that can be used by applications to flexibly determine actions.
The convenient StatementAwareUpdateListener interface is a listener that receives the statement itself and subscribers can accept EPStatement as a parameter.
The insert into-clause can be used to send results into a further stream and input and output adapters or data flows can exist to process output events from that stream.
Also the data flow EPStatementSource operator can be used to hook up actions declaratively.
The EPStatementStateListener can inform your application of new statements coming online.
In this section we look at the output of a very simple EPL statement. The statement selects an event stream without using a data window and without applying any filtering, as follows:
select * from Withdrawal
This statement selects all Withdrawal events. Every time the engine processes an event of type Withdrawal or any sub-type of Withdrawal, it invokes all update listeners, handing the new event to each of the statement's listeners.
The term insert stream denotes the new events arriving, and entering a data window or aggregation. The insert stream in this example is the stream of arriving Withdrawal events, and is posted to listeners as new events.
The diagram below shows a series of Withdrawal events 1 to 6 arriving over time. The number in parenthesis is the withdrawal amount, an event property that is used in the examples that discuss filtering.
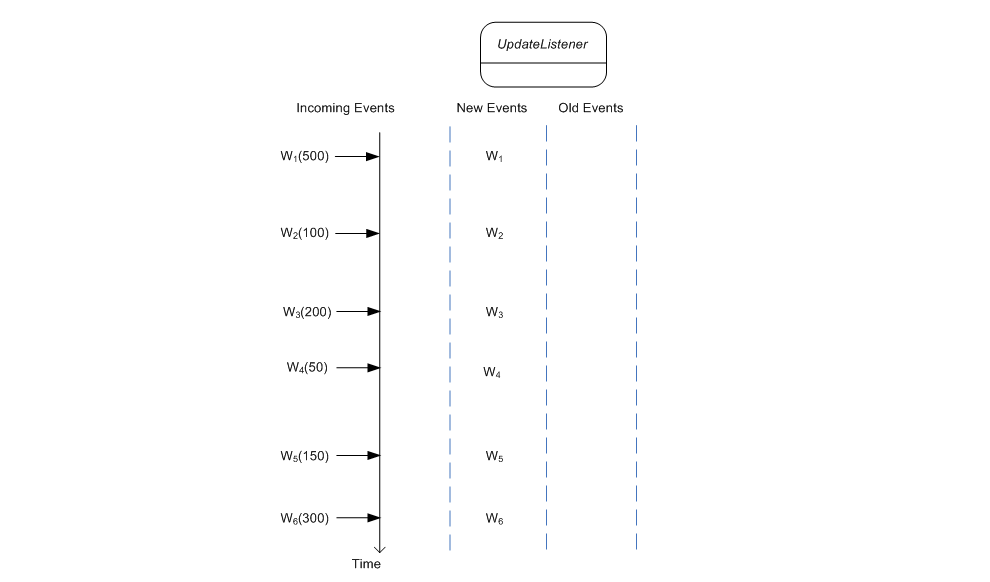
The example statement above results in only new events and no old events posted by the engine to the statement's listeners.
A length window instructs the engine to only keep the last N events for a stream. The next statement applies a length window onto the Withdrawal event stream. The statement serves to illustrate the concept of data window and events entering and leaving a data window:
select * from Withdrawal#length(5)
The size of this statement's length window is five events. The engine enters all arriving Withdrawal events into the length window. When the length window is full, the oldest Withdrawal event is pushed out the window. The engine indicates to listeners all events entering the window as new events, and all events leaving the window as old events.
While the term insert stream denotes new events arriving, the term remove stream denotes events leaving a data window, or changing aggregation values. In this example, the remove stream is the stream of Withdrawal events that leave the length window, and such events are posted to listeners as old events.
The next diagram illustrates how the length window contents change as events arrive and shows the events posted to an update listener.
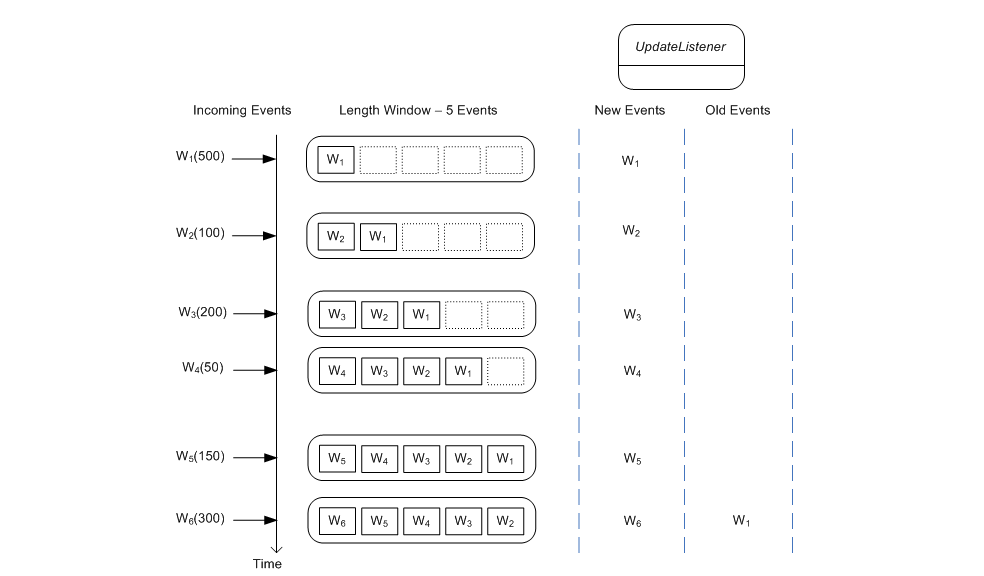
As before, all arriving events are posted as new events to listeners. In addition, when event W1 leaves the length window on arrival of event W6, it is posted as an old event to listeners.
Similar to a length window, a time window also keeps the most recent events up to a given time period. A time window of 5 seconds, for example, keeps the last 5 seconds of events. As seconds pass, the time window actively pushes the oldest events out of the window resulting in one or more old events posted to update listeners.
Note
Note: By default the engine only delivers the insert stream to listeners and observers. EPL supports optionalistream, irstream and rstream keywords on select-clauses and on insert-into clauses to control which stream to deliver, see Section 5.3.7, “Selecting insert and remove stream events”. There is also a related, engine-wide configuration setting described in Section 16.4.20, “Engine Settings related to Stream Selection”.
Filters to event streams allow filtering events out of a given stream before events enter a data window (if there are data windows defined in your query). The statement below shows a filter that selects Withdrawal events with an amount value of 200 or more.
select * from Withdrawal(amount>=200)#length(5)
With the filter, any Withdrawal events that have an amount of less then 200 do not enter the length window and are therefore not passed to update listeners. Filters are discussed in more detail in Section 5.4.1, “Filter-based Event Streams” and Section 7.4, “Filter Expressions In Patterns”.
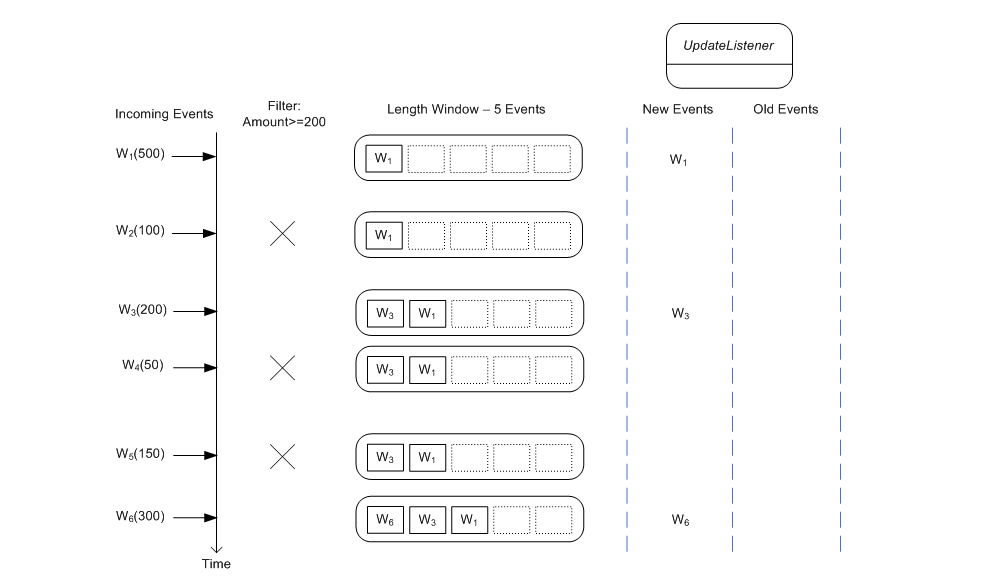
The where-clause and having-clause in statements eliminate potential result rows at a later stage in processing, after events have been processed into a statement's data window or other views.
The next statement applies a where-clause to Withdrawal events. Where-clauses are discussed in more detail in Section 5.5, “Specifying Search Conditions: the Where Clause”.
select * from Withdrawal#length(5) where amount >= 200
The where-clause applies to both new events and old events. As the diagram below shows, arriving events enter the window however only events that pass the where-clause are handed to update listeners. Also, as events leave the data window, only those events that pass the conditions in the where-clause are posted to listeners as old events.
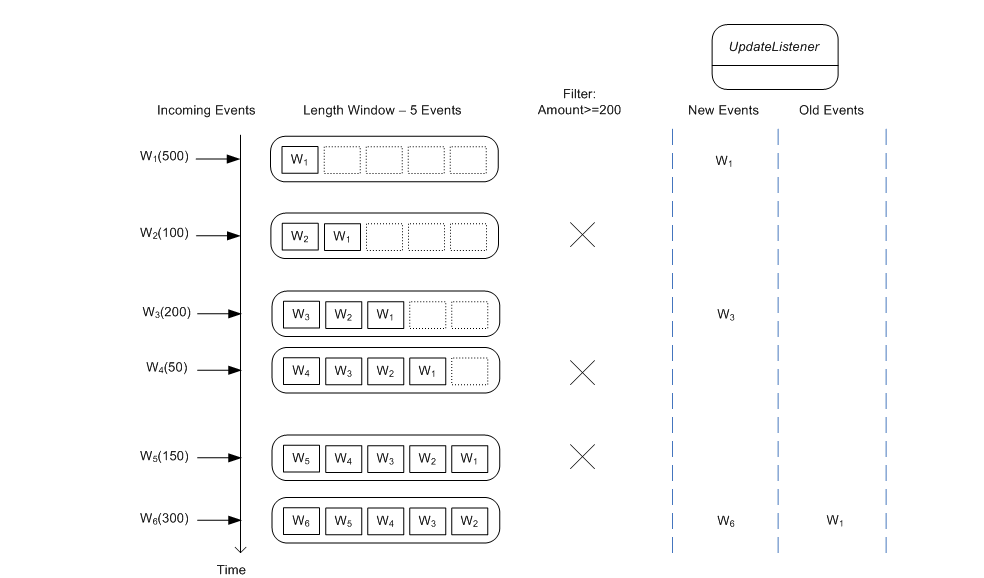
In this section we explain the output model of statements employing a time window view and a time batch view.
A time window is a moving window extending to the specified time interval into the past based on the system time. Time windows enable us to limit the number of events considered by a query, as do length windows.
As a practical example, consider the need to determine all accounts where the average withdrawal amount per account for the last 4 seconds of withdrawals is greater then 1000. The statement to solve this problem is shown below.
select account, avg(amount) from Withdrawal#time(4 sec) group by account having amount > 1000
The next diagram serves to illustrate the functioning of a time window. For the diagram, we assume a query that simply selects the event itself and does not group or filter events.
select * from Withdrawal#time(4 sec)
The diagram starts at a given time t and displays the contents of the time window at t + 4 and t + 5 seconds and so on.
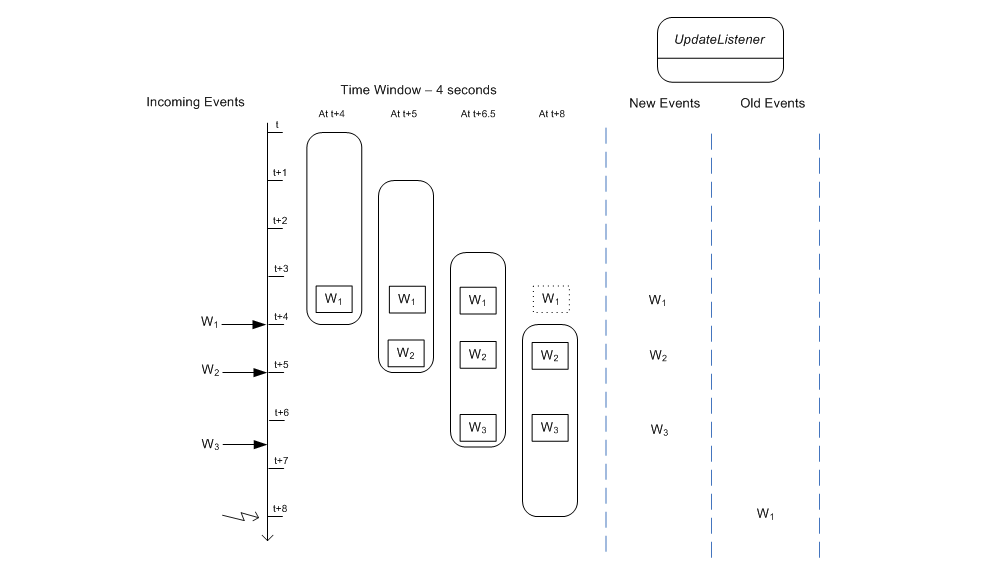
The activity as illustrated by the diagram:
At time
t + 4 secondsan eventW1arrives and enters the time window. The engine reports the new event to update listeners.At time
t + 5 secondsan eventW2arrives and enters the time window. The engine reports the new event to update listeners.At time
t + 6.5 secondsan eventW3arrives and enters the time window. The engine reports the new event to update listeners.At time
t + 8 secondseventW1leaves the time window. The engine reports the event as an old event to update listeners.
The time batch view buffers events and releases them every specified time interval in one update. Time windows control the evaluation of events, as does the length batch window.
The next diagram serves to illustrate the functioning of a time batch view. For the diagram, we assume a simple query as below:
select * from Withdrawal#time_batch(4 sec)
The diagram starts at a given time t and displays the contents of the time window at t + 4 and t + 5 seconds and so on.
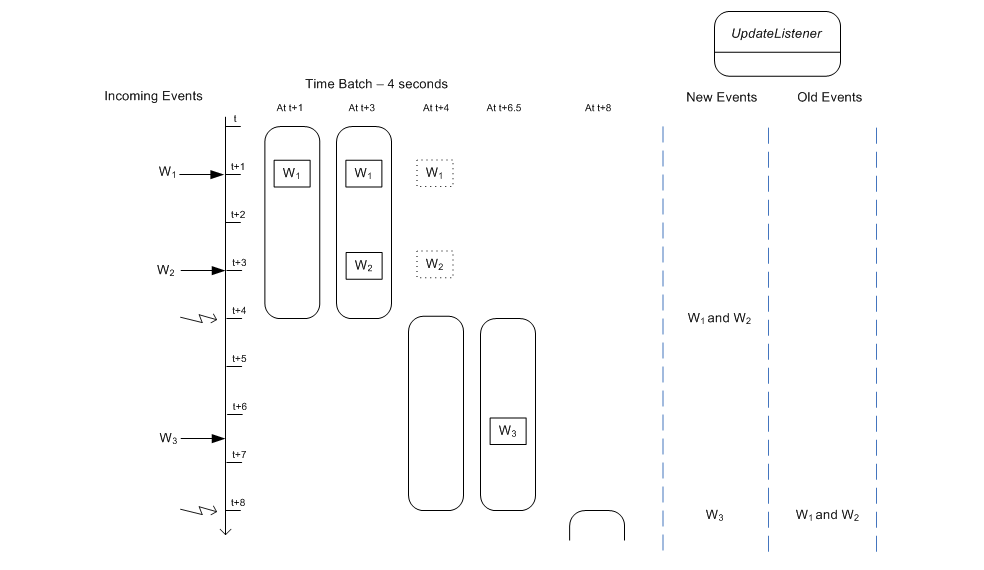
The activity as illustrated by the diagram:
At time
t + 1 secondsan eventW1arrives and enters the batch. No call to inform update listeners occurs.At time
t + 3 secondsan eventW2arrives and enters the batch. No call to inform update listeners occurs.At time
t + 4 secondsthe engine processes the batched events and a starts a new batch. The engine reports eventsW1andW2to update listeners.At time
t + 6.5 secondsan eventW3arrives and enters the batch. No call to inform update listeners occurs.At time
t + 8 secondsthe engine processes the batched events and a starts a new batch. The engine reports the eventW3as new data to update listeners. The engine reports the eventsW1andW2as old data (prior batch) to update listeners.
The built-in data windows that act on batches of events are the win:time_batch and the win:length_batch views, among others. The win:time_batch data window collects events arriving during a given time interval and posts collected events as a batch to listeners at the end of the time interval. The win:length_batch data window collects a given number of events and posts collected events as a batch to listeners when the given number of events has collected.
For more detailed information on batch windows please see Section 13.2, “A Note on Batch Windows”.
Related to batch data windows is output rate limiting. While batch data windows retain events the output clause offered by output rate limiting can control or stabilize the rate at which events are output, see Section 5.7, “Stabilizing and Controlling Output: the Output Clause”.
Let's look at how a time batch window may be used:
select account, amount from Withdrawal#time_batch(1 sec)
The above statement collects events arriving during a one-second interval, at the end of which the engine posts the collected events as new events (insert stream) to each listener. The engine posts the events collected during the prior batch as old events (remove stream). The engine starts posting events to listeners one second after it receives the first event and thereon.
For statements containing aggregation functions and/or a group by clause, the engine posts consolidated aggregation results for an event batch. For example, consider the following statement:
select sum(amount) as mysum from Withdrawal#time_batch(1 sec)
Note that output rate limiting also generates batches of events following the output model as discussed here.
Statements that aggregate events via aggregation functions also post remove stream events as aggregated values change.
Consider the following statement that alerts when 2 Withdrawal events have been received:
select count(*) as mycount from Withdrawal having count(*) = 2
When the engine encounters the second withdrawal event, the engine posts a new event to update listeners. The value of the "mycount" property on that new event is 2.
Additionally, when the engine encounters the third Withdrawal event, it posts an old event to update listeners containing the prior value of the count, if specifing the rstream keyword in the select clause to select the remove stream. The value of the "mycount" property on that old event is also 2.
Note the statement above does not specify a data window and thereby counts all arriving events since statement start. The statement above retains no events and its memory allocation is only the aggregation state, i.e. a single long value to represent count(*).
The istream or rstream keyword can be used to eliminate either new events or old events posted to listeners. The next statement uses the istream keyword causing the engine to call the listener only once when the second Withdrawal event is received:
select istream count(*) as mycount from Withdrawal having count(*) = 2
Following SQL (Standard Query Language) standards for queries against relational databases, the presence or absence of aggregation functions and the presence or absence of the group by clause and group_by named parameters for aggregation functions dictates the number of rows posted by the engine to listeners. The next sections outline the output model for batched events under aggregation and grouping. The examples also apply to data windows that don't batch events and post results continously as events arrive or leave data windows. The examples also apply to patterns providing events when a complete pattern matches.
In summary, as in SQL, if your query only selects aggregation values, the engine provides one row of aggregated values. It provides that row every time the aggregation is updated (insert stream), which is when events arrive or a batch of events gets processed, and when the events leave a data window or a new batch of events arrives. The remove stream then consists of prior aggregation values.
Also as in SQL, if your query selects non-aggregated values along with aggregation values in the select clause, the engine provides a row per event. The insert stream then consists of the aggregation values at the time the event arrives, while the remove stream is the aggregation value at the time the event leaves a data window, if any is defined in your query.
EPL allows each aggregation function to specify its own grouping criteria. Please find further information in Section 5.6.4, “Specifying grouping for each aggregation function”.
The documentation provides output examples for query types in Appendix A, Output Reference and Samples, and the next sections outlines each query type.
An example statement for the un-aggregated and un-grouped case is as follows:
select * from Withdrawal#time_batch(1 sec)
At the end of a time interval, the engine posts to listeners one row for each event arriving during the time interval.
The appendix provides a complete example including input and output events over time at Section A.2, “Output for Un-aggregated and Un-grouped Queries”.
If your statement only selects aggregation values and does not group, your statement may look as the example below:
select sum(amount) from Withdrawal#time_batch(1 sec)
At the end of a time interval, the engine posts to listeners a single row indicating the aggregation result. The aggregation result aggregates all events collected during the time interval.
The appendix provides a complete example including input and output events over time at Section A.3, “Output for Fully-aggregated and Un-grouped Queries”.
If any aggregation functions specify the group_by parameter and a dimension, for example sum(amount, group_by:account),
the query executes as an aggregated and grouped query instead.
If your statement selects non-aggregated properties and aggregation values, and does not group, your statement may be similar to this statement:
select account, sum(amount) from Withdrawal#time_batch(1 sec)
At the end of a time interval, the engine posts to listeners one row per event. The aggregation result aggregates all events collected during the time interval.
The appendix provides a complete example including input and output events over time at Section A.4, “Output for Aggregated and Un-grouped Queries”.
If your statement selects aggregation values and all non-aggregated properties in the select clause are listed in the group by clause, then your statement may look similar to this example:
select account, sum(amount) from Withdrawal#time_batch(1 sec) group by account
At the end of a time interval, the engine posts to listeners one row per unique account number. The aggregation result aggregates per unique account.
The appendix provides a complete example including input and output events over time at Section A.5, “Output for Fully-aggregated and Grouped Queries”.
If any aggregation functions specify the group_by parameter and a dimension other than group by dimension(s),
for example sum(amount, group_by:accountCategory), the query executes as an aggregated and grouped query instead.
If your statement selects non-aggregated properties and aggregation values, and groups only some properties using the group by clause, your statement may look as below:
select account, accountName, sum(amount) from Withdrawal#time_batch(1 sec) group by account
At the end of a time interval, the engine posts to listeners one row per event. The aggregation result aggregates per unique account.
The appendix provides a complete example including input and output events over time at Section A.6, “Output for Aggregated and Grouped Queries”.
An event sent by your application or generated by statements is visible to all other statements in the same engine instance. Similarly, current time (the time horizon) moves forward for all statements in the same engine instance. Please see the Chapter 15, API Reference chapter for how to send events and how time moves forward through system time or via simulated time, and the possible threading models.
Within an Esper engine instance you can additionally control event visibility and current time on a statement level, under the term isolated service as described in Section 15.9, “Service Isolation”.
An isolated service provides a dedicated execution environment for one or more statements. Events sent to an isolated service are visible only within that isolated service. In the isolated service you can move time forward at the pace and resolution desired without impacting other statements that reside in the engine runtime or other isolated services. You can move statements between the engine and an isolated service.