- 2.1. Introduction
- 2.2. Basic Select
- 2.3. Basic Aggregation
- 2.4. Basic Filter
- 2.5. Basic Filter and Aggregation
- 2.6. Basic Data Window
- 2.7. Basic Data Window and Aggregation
- 2.8. Basic Filter, Data Window and Aggregation
- 2.9. Basic Where-Clause
- 2.10. Basic Time Window and Aggregation
- 2.11. Basic Partitioned Query
- 2.12. Basic Output-Rate-Limited Query
- 2.13. Basic Partitioned and Output-Rate-Limited Query
- 2.14. Basic Named Windows and Tables
- 2.15. Basic Aggregated Query Types
- 2.16. Basic Match-Recognize Patterns
- 2.17. Basic EPL Patterns
- 2.18. Basic Indexes
For NEsper .NET also see Section I.11, “.NET Basic Concepts”.
Esper is a container for EPL queries. EPL queries are continuous query statements that analyze events and time and that detect situations. Esper contains the EPL queries as it manages their lifecycle and execution.
You interact with Esper by managing EPL queries and callbacks and by sending events and advancing time.
Table 2.1. Interacting With Esper
| What | How |
|---|---|
| EPL | First, deploy EPL queries, please refer to Chapter 5, EPL Reference: Clauses and the API at Section 14.3, “The Administrative Interface”. |
| Callbacks | Second, attach executable code that your application provides to receive output, please refer to Section 14.3.2, “Receiving Statement Results”. |
| Events | Next, send events using the runtime API, please refer to Section 14.4, “The Runtime Interface”. |
| Time | Next, advance time using the runtime API or system time, please refer to Section 14.8, “Controlling Time-Keeping”. |
Esper contains queries like so:
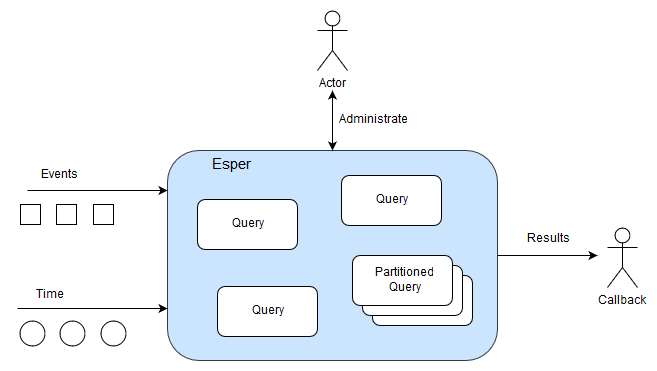
When time passes or an event arrives Esper evaluates only those queries that need to see such event or time. Esper analyzes EPL queries, performs query planning and utilizes data structures to avoid unneeded evaluation.
EPL queries can be partitioned. A partitioned query can have multiple partitions. For example, there could be partition for each room in a building. For a building with 10 rooms you could have one EPL query that has 10 partitions. Please refer to Chapter 4, Context and Context Partitions.
An EPL query that is not partitioned implicitly has one partition. Upon creating the un-partitioned EPL query Esper allocates the single partition. Upon destroying the un-partitioned EPL query Esper destroys the partition.
A partition (or context partition) is where Esper keeps the state. In the picture above there are three un-partitioned queries and one partitioned query that has three partitions.
The next sections discuss various easily-understood EPL queries.
The sections illustrate how queries behave, the information that Esper passes to callbacks (the output) and what information Esper remembers for queries (the state, all state lives in a partition).
The sample queries assume an event type by name Withdrawal that has account and amount properties.
This EPL query selects all Withdrawal events.
select * from Withdrawal
Upon a new Withdrawal event arriving, Esper passes the arriving event, unchanged and the same object reference, to callbacks.
After that Esper effectively forgets the current event.
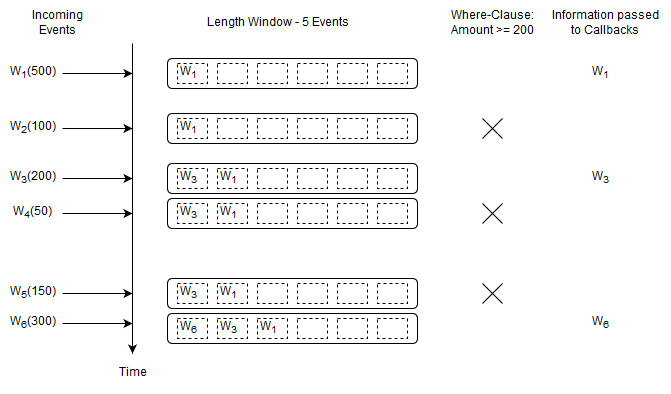
The diagram below shows a series of Withdrawal events (1 to 6) arriving over time.
In the picture the Wn stands for a specific Withdrawal event arriving. The number in parenthesis is the withdrawal amount.
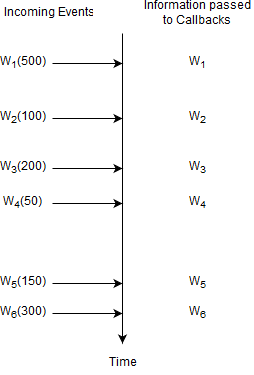
For this query, Esper remembers no information and does not remember any events. A query where Esper does not need to remember any information at all is a query without state (a stateless query).
The term insert stream is a name for the stream of new events that are arriving. The insert stream in this example is the stream of arriving Withdrawal events.
An aggregation function is a function that groups multiple events together to form a single value. Please find more information at Section 10.2, “Aggregation Functions”.
This query selects a count and a total amount of all Withdrawal events.
select count(*), sum(amount) from Withdrawal
Upon a new Withdrawal event arriving, Esper increments the count and adds the amount to a running total. It passes the new count and total to callbacks.
After that Esper effectively forgets the current event and does not remember any events at all, but does remember the current count and total.
Here, Esper only remembers the current number of events and the total amount.
The count is a single long-type value and the total is a single double-type value (assuming amount is a double-value, the total can be BigDecimal as applicable).
This query is not stateless and the state consists of a long-typed value and a double-typed value.
Upon a new Withdrawal event arriving, Esper increases the count by one and adds the amount to the running total. Esper does not re-compute the count and total because it does not remember events.
In general, Esper does not re-compute aggregations (unless otherwise indicated). Instead, Esper adds (increments, enters, accumulates) data to aggregation state and subtracts (decrements, removes, reduces, decreases) from aggregation state.
Place filter expressions in parenthesis after the event type name. For further information see Section 5.4.1, “Filter-Based Event Streams”.
This statement selects Withdrawal events that have an amount of 200 or higher:
select * from Withdrawal(amount >= 200)
Upon a new Withdrawal event with an amount of 200 or higher arriving, Esper passes the arriving event to callbacks.
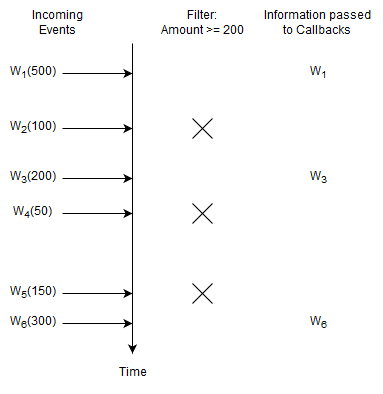
For this query, Esper remembers no information and does not remember any events.
You may ask what happens for Withdrawal events with an amount of less than 200. The answer is that the EPL query itself does not even see such events. This is because Esper knows to discard such events right away
and the EPL query does not even know about such events. Esper discards unneeded events very fast enabled by EPL query analysis, planning and suitable data structures.
This statement selects the count and the total amount for Withdrawal events that have an amount of 200 or higher:
select count(*), sum(amount) from Withdrawal(amount >= 200)
Upon a new Withdrawal event with an amount of 200 or higher arriving, Esper increments the count and adds the amount to the running total. Esper passes the count and total to callbacks.
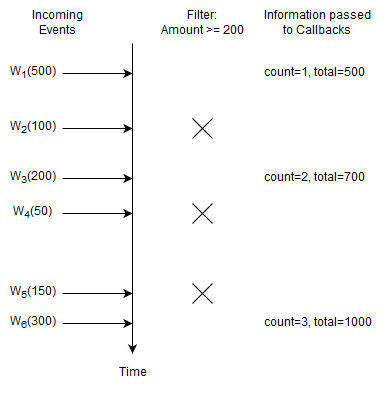
In this example Esper only remembers the count and total and again does not remember events. The engine discards Withdrawal events with an amount of less than 200.
A data window, or window for short, retains events for the purpose of aggregation, join, match-recognize patterns, subqueries, iterating via API and output-snapshot. A data window defines which subset of events to retain. For example, a length window keeps the last N events and a time window keeps the last N seconds of events. See Chapter 13, EPL Reference: Data Windows for details.
This query selects all Withdrawal events and instructs Esper to remember the last five events.
select * from Withdrawal#length(5)
Upon a new Withdrawal event arriving, Esper adds the event to the length window. It also passes the same event to callbacks.
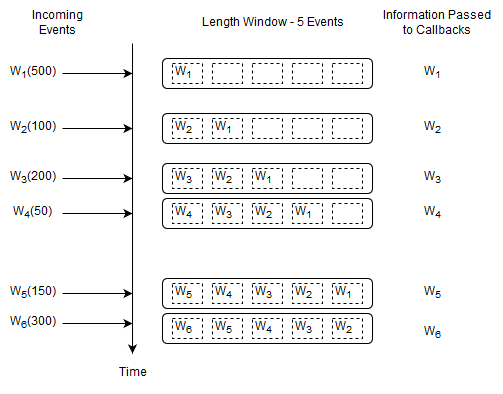
Upon arrival of event W6, event W1 leaves the length window. We use the term expires to say that an event leaves a data window. We use the term remove stream to describe the stream of events leaving a data window.
Esper remembers up to five events in total (the last five events). At the start of the query the data window is empty. By itself, keeping the last five events may not sound useful. But in connection with a join, subquery or match-recognize pattern for example a data window tells the engine which events you want to query.
Note
By default the engine only delivers the insert stream to listeners and observers. EPL supports optionalistream, irstream and rstream keywords for select- and insert-into clauses to control which streams to deliver, see Section 5.3.7, “Selecting Insert and Remove Stream Events”.
This query outputs the count and total of the last five Withdrawal events.
select count(*), sum(amount) from Withdrawal#length(5)
Upon a new Withdrawal event arriving, Esper adds the event to the length window, increases the count by one and adds the amount to the current total amount.
Upon a Withdrawal event leaving the data window, Esper decreases the count by one and subtracts its amount from the current total amount.
It passes the running count and total to callbacks.
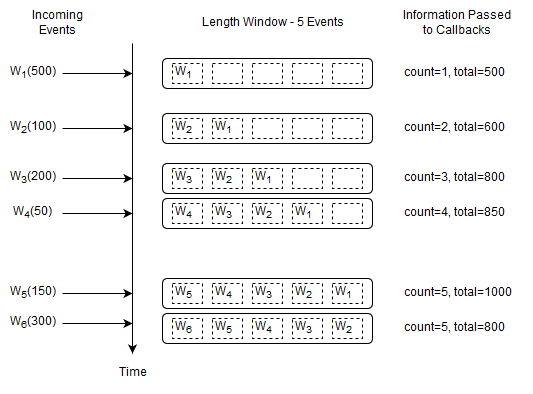
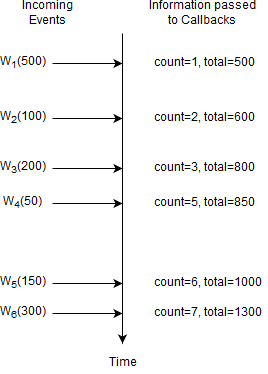
Before the arrival of event W6 the current count is five and the running total amount is 1000. Upon arrival of event W6 the following takes place:
Esper determines that event W1 leaves the length window.
To account for the new event W6, Esper increases the count by one and adds 300 to the running total amount.
To account for the expiring event W1, Esper decreases the count by one and subtracts 500 from the running total amount.
The output is a count of five and a total of 800 as a result of
1000 + 300 - 500.
Esper adds (increments, enters, accumulates) insert stream events into aggregation state and subtracts (decrements, removes, reduces, decreases) remove stream events from aggregation state. It thus maintains aggregation state in an incremental fashion.
For this query, once the count reaches 5, the count will always remain at 5.
The information that Esper remembers for this query is the last five events and the current long-typed count and double-typed total.
Tip
Use the irstream keyword to receive both the current as well as the previous aggregation value for aggregating queries.
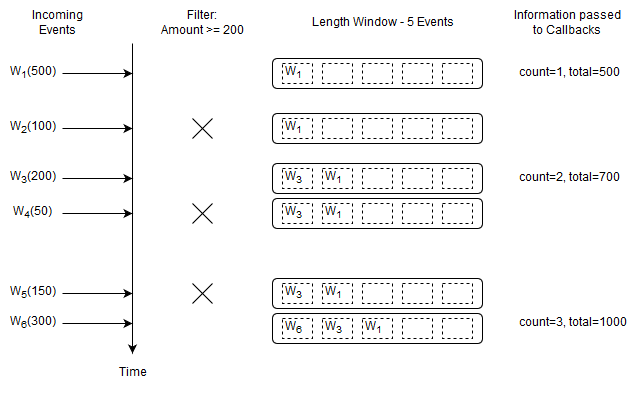
The following query outputs the count and total of the last five Withdrawal events considering only those Withdrawal events that have an amount of at least 200:
select count(*), sum(amount) from Withdrawal(amount>=200)#length(5)
Upon a new Withdrawal event arriving, and only if that Withdrawal event has an amount of 200 or more, Esper adds the event to the length window, increases the count by one and adds the amount to the current total amount.
Upon a Withdrawal event leaving the data window, Esper decreases the count by one and subtracts its amount from the current total amount.
It passes the running count and total to callbacks.
For queries without a data window, the where-clause behaves the same as the filter expressions that are placed in parenthesis.
The following two queries are fully equivalent because of the absence of a data window (the .... means any select-clause expressions):
select .... from Withdrawal(amount > 200) // equivalent to select .... from Withdrawal where amount > 200
Note
In Esper, the where-clause is typically used for correlation in a join or subquery. Filter expressions should be placed right after the event type name in parenthesis.
The next statement applies a where-clause to Withdrawal events. Where-clauses are discussed in more detail in Section 5.5, “Specifying Search Conditions: The Where Clause”.
select * from Withdrawal#length(5) where amount >= 200
The where-clause applies to both new events and expiring events. Only events that pass the where-clause are passed to callbacks.
A time window is a data window that extends the specified time interval into the past. More information on time windows can be found at Section 13.3.3, “Time Window (time or win:time)”.
The next query selects the count and total amount of Withdrawal events considering the last four seconds of events.
select count(*), total(amount) from Withdrawal#time(4)
The diagram starts at a given time t and displays the contents of the time window at t + 4 and t + 5 seconds and so on.
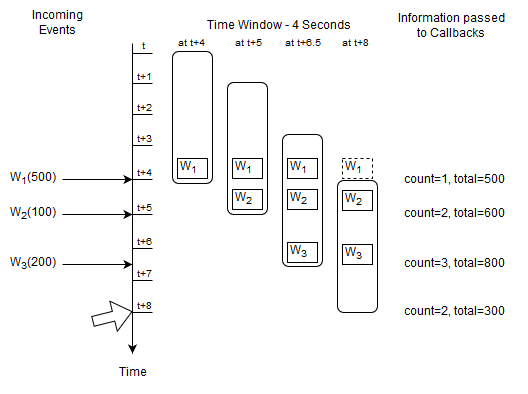
The activity as illustrated by the diagram:
At time
t + 4 secondsan eventW1arrives and the output is a count of one and a total of 500.At time
t + 5 secondsan eventW2arrives and the output is a count of two and a total of 600.At time
t + 6.5 secondsan eventW3arrives and the output is a count of three and a total of 800.At time
t + 8 secondseventW1expires and the output is a count of two and a total of 300.
For this query Esper remembers the last four seconds of Withdrawal events as well as the long-typed count and the double-typed total amount.
Tip
Time can have a millisecond or microsecond resolution.
The queries discussed so far are not partitioned. A query that is not partitioned implicitly has one partition. Upon creating the un-partitioned EPL query Esper allocates the single partition and it destroys the partition when your application destroys the query.
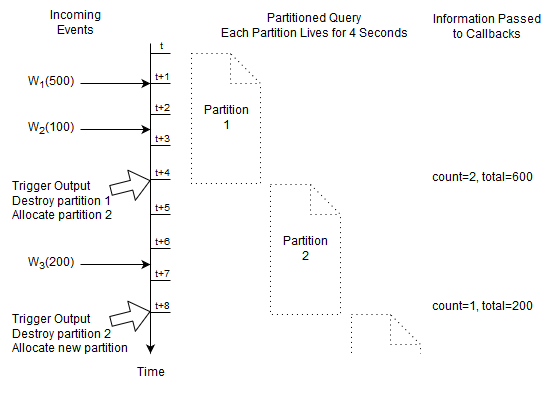
A partitioned query is handy for batch processing, sessions, resetting and start/stop of your analysis. For partitioned queries you must specify a context. A context defines how partitions are allocated and destroyed. Additional information about partitioned queries and contexts can be found at Chapter 4, Context and Context Partitions.
We shall have a single partition that starts immediately and ends after four seconds:
create context Batch4Seconds start @now end after 4 sec
The next query selects the count and total amount of Withdrawal events that arrived since the last reset (resets are at t, t+4, t+8 as so on), resetting each four seconds:
context Batch4Seconds select count(*), total(amount) from Withdrawal
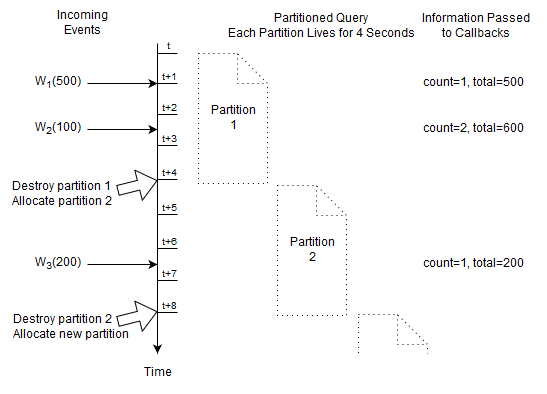
At time t + 4 seconds and t + 8 seconds the engine destroys the current partition. This discards the current count and running total.
The engine immediately allocates a new partition and the count and total start fresh at zero.
For this query Esper only remembers the count and running total, and the fact how long a partition lives.
All the previous queries had continuous output. In other words, in each of previous queries output occurred as a result of a new event arriving. Use output rate limiting to output when a condition occurs, as described in Section 5.7, “Stabilizing and Controlling Output: The Output Clause”.
The next query outputs the last count and total of all Withdrawal events every four seconds:
select count(*), total(amount) from Withdrawal output last every 4 seconds
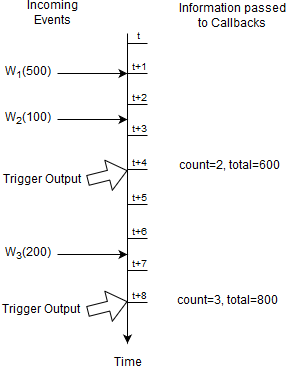
At time t + 4 seconds and t + 8 seconds the engine outputs the last aggregation values to callbacks.
For this query Esper only remembers the count and running total, and the fact when output shall occur.
Use a partitioned query with output rate limiting to output-and-reset. This allows you to form batches, analyze a batch and then forget all such state in respect to that batch, continuing with the next batch.
The next query selects the count and total amount of Withdrawal events that arrived within the last four seconds at the end of four seconds, resetting after output:
create context Batch4Seconds start @now end after 4 sec
context Batch4Seconds select count(*), total(amount) from Withdrawal output last when terminated
At time t + 4 seconds and t + 8 seconds the engine outputs the last aggregation values to callbacks, and resets the current count and total.
For this query Esper only remembers the count and running total, and the fact when the output shall occur and how long a partition lives.
A named window is a global data window that can take part in many queries, and that can be selected-from, inserted- into and deleted-from by multiple EPL queries. Named windows can be queried with fire-and-forget queries through the API and inward-facing JDBC driver. The documentation link is Chapter 6, EPL Reference: Named Windows and Tables.
Create a named window, for example, to hold alarm information:
create window AlertNamedWindow as (origin string, priority string, alarmNumber long)
Use on-merge to insert and update the named window.
on Alert as a1 merge AlertNamedWindow as a2 where a1.alarmNumber = a2.alarmNumber when not matched then insert select *
The following query outputs the current count of rows in the named window:
select count(*) from AlertNamedWindow
Tables are similar to named window however have a well-defined primary-key and can share aggregated state, while named windows only share a subset of events.
The expressions in the select-clause, the use of aggregation functions and the group-by-clause are relevant to EPL query design. The overview herein is especially relevant to joins, on-trigger, output-rate-limiting and batch data windows.
If your query only selects aggregation values, the engine outputs one row (or zero rows in a join).
Without a group-by clause, if your query selects non-aggregated values along with aggregation values, the engine outputs a row per event.
With a group-by clause, if your query selects non-aggregated values that are all in the group-by-clause, the engine outputs a row per group.
With a group-by clause, if your query selects non-aggregated values and not all non-aggregated values are in the group-by-clause, the engine outputs a row per event.
EPL allows each aggregation function to specify its own grouping criteria. Please find further information in Section 5.6.4, “Specifying Grouping for Each Aggregation Function”. The documentation provides output examples for query types in Appendix A, Output Reference and Samples, and the next sections outlines each query type.
The examples below assume BankInformationWindow is a named window defined elsewhere.
The examples use a join to illustrate. Joins are further described in Section 5.12, “Joining Event Streams”.
An example statement for the un-aggregated and un-grouped case is as follows:
select * from Withdrawal unidirectional, BankInformationWindow
Upon a Withdrawal event coming in, the number of output rows is the number of rows in the BankInformationWindow.
The appendix provides a complete example including input and output events over time at Section A.2, “Output for Un-Aggregated and Un-Grouped Queries”.
If your statement only selects aggregation values and does not group, your statement may look as the example below:
select sum(amount) from Withdrawal unidirectional, BankInformationWindow
Upon a Withdrawal event coming in, the number of output rows is always zero or one.
The appendix provides a complete example including input and output events over time at Section A.3, “Output for Fully-Aggregated and Un-Grouped Queries”.
If any aggregation functions specify the group_by parameter and a dimension, for example sum(amount, group_by:account),
the query executes as an aggregated and grouped query instead.
If your statement selects non-aggregated properties and aggregation values, and does not group, your statement may be similar to this statement:
select account, sum(amount) from Withdrawal unidirectional, BankInformationWindow
Upon a Withdrawal event coming in, the number of output rows is the number of rows in the BankInformationWindow.
The appendix provides a complete example including input and output events over time at Section A.4, “Output for Aggregated and Un-Grouped Queries”.
If your statement selects aggregation values and all non-aggregated properties in the select clause are listed in the group by clause, then your statement may look similar to this example:
select account, sum(amount) from Withdrawal unidirectional, BankInformationWindow group by account
Upon a Withdrawal event coming in, the number of output rows is one row per unique account number.
The appendix provides a complete example including input and output events over time at Section A.5, “Output for Fully-Aggregated and Grouped Queries”.
If any aggregation functions specify the group_by parameter and a dimension other than group by dimension(s),
for example sum(amount, group_by:accountCategory), the query executes as an aggregated and grouped query instead.
If your statement selects non-aggregated properties and aggregation values, and groups only some properties using the group by clause, your statement may look as below:
select account, accountName, sum(amount) from Withdrawal unidirectional, BankInformationWindow group by account
Upon a Withdrawal event coming in, the number of output rows is the number of rows in the BankInformationWindow.
The appendix provides a complete example including input and output events over time at Section A.6, “Output for Aggregated and Grouped Queries”.
Esper offers the standardized match-recognize syntax for finding patterns among events. A match-recognize pattern is very similar to a regular-expression pattern.
The below query is a sample match-recognize pattern. It detects a pattern that may be present in the events held by the named window as declared above. It looks for two immediately-followed events, i.e. with no events in-between for the same origin. The first of the two events must have high priority and the second of the two events must have medium priority.
select * from AlertNamedWindow
match_recognize (
partition by origin
measures a1.origin as origin, a1.alarmNumber as alarmNumber1, a2.alarmNumber as alarmNumber2
pattern (a1 a2)
define
a1 as a1.priority = 'high',
a2 as a2.priority = 'medium'
)Esper offers the EPL pattern language, a versatile and expressive syntax for finding time and property relationships between events of many streams.
Event patterns match when an event or multiple events occur that match the pattern's definition, in a bottom-up fashion. Pattern expressions can consist of filter expressions combined with pattern operators. Expressions can contain further nested pattern expressions by including the nested expression(s) in parenthesis.
There are five types of operators:
Operators that control pattern finder creation and termination:
everyLogical operators:
and,or,notTemporal operators that operate on event order:
->(the followed-by operator)Guards are where-conditions that cause termination of pattern subexpressions, such as
timer:withinObservers that observe time events, such as
timer:interval(an interval observer),timer:at(a crontab-like observer)
A sample pattern that alerts on each IBM stock tick with a price greater than 80 and within the next 60 seconds:
every StockTickEvent(symbol="IBM", price>80) where timer:within(60 seconds)
A sample pattern that alerts every five minutes past the hour:
every timer:at(5, *, *, *, *)
A sample pattern that alerts when event A occurs, followed by either event B or event C:
A -> ( B or C)
A pattern where a property of a following event must match a property from the first event:
every a=EventX -> every b=EventY(objectID=a.objectID)
Esper, depending on the EPL statements, builds and maintains two kinds of indexes: filter indexes and event indexes.
Esper builds and maintains indexes for efficiency so as to achieve good performance.
The following table compares the two kinds of indexes:
Table 2.2. Kinds of Indexes
| Filter Indexes | Event Indexes | |
|---|---|---|
| Improve the speed of | Matching incoming events to currently-active filters that shall process the event | Lookup of rows |
| Similar to | A structured registry of callbacks; or content-based routing | Database index |
| Index stores values of | Values provided by expressions | Values for certain column(s) |
| Index points to | Currently-active filters | Rows |
| Comparable to | A sieve or a switchboard | An index in a book |
Filter indexes organize filters so that they can be searched efficiently. Filter indexes link back to the statement that the filter(s) come from.
We use the term filter or filter criteria to mean the selection predicate, such as symbol=“google” and price > 200 and volume > 111000.
Statements provide filter criteria in the from-clause, and/or in EPL patterns and/or in context declarations.
Please see Section 5.4.1, “Filter-Based Event Streams”, Section 7.4, “Filter Expressions in Patterns” and Section 4.2.7.1, “Filter Context Condition”.
When the engine receives an event, it consults the filter indexes to determine which statements, if any, must process the event.
The purpose of filter indexes is to enable:
Efficient matching of events to only those statements that need them.
Efficient discarding of events that are not needed by any statement.
Efficient evaluation with best case approximately O(1) to O(log n) i.e. in the best case executes in approximately the same time regardless of the size of the input data set which is the number of active filters.
Filter index building is a result of the engine analyzing the filter criteria in the from-clause and also in EPL patterns. It is done automatically by the engine.
Esper builds and maintains separate sets of filter indexes per event type, when such event type occurs in the from-clause or pattern.
Filter indexes are sharable within the same event type filter. Thus various from-clauses and patterns that refer for the same event type can contribute to the same set of filter indexes.
Esper builds filter indexes in a nested fashion: Filter indexes may contain further filter indexes, forming a tree-like structure, a filter index tree. The nesting of indexes is beyond the introductory discussion provided here.
The from-clause in a statement and, in special cases, also the where-clause provide filter criteria that the engine analyzes and for which it builds filter indexes.
For example, assume the WithdrawalEvent has an account field. You could create three EPL statements like so:
@name('A') select * from WithdrawalEvent(account = 1)@name('B') select * from WithdrawalEvent(account = 1)@name('C') select * from WithdrawalEvent(account = 2)
In this example, both statement A and statement B register interest in WithdrawalEvent events that have an account value of 1.
Statement C registers interest in WithdrawalEvent events that have an account value of 2.
The below table is a sample filter index for the three statements:
Table 2.3. Sample Filter Index Multi-Statement Example
Value of account | Filter |
|---|---|
1 | Statement A, Statement B |
2 | Statement C |
When a Withdrawal event arrives, the engine extracts the account and performs a lookup into above table.
If there are no matching rows in the table, for example when the account is 3, the engine knows that there is no further processing for the event.
As part of a pattern you may specify event types and filter criteria. The engine analyzes patterns and determines filter criteria for filter index building.
Consider the following example pattern that fires for each WithdrawalEvent that is followed by another WithdrawalEvent for the same account value:
@name('P') select * from pattern [every w1=WithdrawalEvent -> w2=WithdrawalEvent(account = w.account)]
Upon creating the above statement, the engine starts looking for WithdrawalEvent events. At this time there is only one active filter:
A filter looking for
WithdrawalEventevents regardless of account id.
Assume a WithdrawalEvent Wa for account 1 arrives. The engine then activates a filter looking for another WithdrawalEvent for account 1.
At this time there are two active filters:
A filter looking for
WithdrawalEventevents regardless of account id.A filter looking for
WithdrawalEvent(account=1)associated tow1=Wa.
Assume another WithdrawalEvent Wb for account 1 arrives. The engine then activates a filter looking for another WithdrawalEvent for account 1.
At this time there are three active filters:
A filter looking for
WithdrawalEventevents regardless of account id.A filter looking for
WithdrawalEvent(account=1)associated tow1=Wa.A filter looking for
WithdrawalEvent(account=1)associated tow2=Wb.
Assume another WithdrawalEvent Wc for account 2 arrives. The engine then activates a filter looking for another WithdrawalEvent for account 2.
At this time there are four active filters:
A filter looking for
WithdrawalEventevents regardless of account id.A filter looking for
WithdrawalEvent(account=1)associated tow1=Wa.A filter looking for
WithdrawalEvent(account=1)associated tow1=Wb.A filter looking for
WithdrawalEvent(account=2)associated tow1=Wc.
The below table is a sample filter index for the pattern after the Wa, Wband Wc events arrived:
Table 2.4. Sample Filter Index Pattern Example
Value of account | Filter |
|---|---|
1 | Statement P Pattern w1=Wa, Statement P Pattern w1=Wb |
2 | Statement P Pattern w1=Wc |
When a Withdrawal event arrives, the engine extracts the account and performs a lookup into above table.
If a matching row is found, the engine can hand off the event to the relevant pattern subexpressions.
This example is similar to the previous example of multiple statements, but instead it declares a context and associates a single statement to the context.
For example, assume the LoginEvent has an account field. You could declare a context initiated by a LoginEvent for a user:
@name('A') create context UserSession initiated by LoginEvent as loginEvent
By associating the statement to the context you can tell the engine to analze per LoginEvent, for example:
@name('B') context UserSession select count(*) from WithdrawalEvent(account = context.loginEvent.account)
Upon creating the above two statements, the engine starts looking for LoginEvent events. At this time there is only one active filter:
A filter looking for
LoginEventevents (any account id).
Assume a LoginEvent La for account 1 arrives. The engine then activates a context partition of statement B and therefore the filter looking for WithdrawalEvent for account 1.
At this time there are two active filters:
A filter looking for
LoginEventevents (any account id).A filter looking for
WithdrawalEvent(account=1)associated tologinEvent=La.
Assume a LoginEvent Lb for account 1 arrives. The engine then activates a context partition of statement B and therefore the filter looking for WithdrawalEvent for account 1.
At this time there are three active filters:
A filter looking for
LoginEventevents (any account id).A filter looking for
WithdrawalEvent(account=1)associated tologinEvent=La.A filter looking for
WithdrawalEvent(account=1)associated tologinEvent=Lb.
Assume a LoginEvent Lc for account 2 arrives. The engine then activates a context partition of statement B and therefore the filter looking for WithdrawalEvent for account 2.
At this time there are four active filters:
A filter looking for
LoginEventevents (any account id).A filter looking for
WithdrawalEvent(account=1)associated tologinEvent=La.A filter looking for
WithdrawalEvent(account=1)associated tologinEvent=Lb.A filter looking for
WithdrawalEvent(account=2)associated tologinEvent=Lc.
The below table is a sample filter index for the three statement context partitions:
Table 2.5. Sample Filter Index Context Example
Value of account | Filter |
|---|---|
1 | Statement B Context Partition #0 loginEvent=La, Statement B Context Partition #1 loginEvent=Lb |
2 | Statement B Context Partition #2 loginEvent=Lc |
When a Withdrawal event arrives, the engine extracts the account and performs a lookup into above table.
It can then hand of the event directly to the relevant statement context partitions, or ignore the event if no rows are found for a given account id.
Event indexes organize certain columns so that they can be searched efficiently. Event indexes link back to the row that the column(s) come from.
As event indexes are similar to database indexes, for this discussion, we use the term column to mean a column in a EPL table or named window and to also mean an event property or field. We use the term row to mean a row in an EPL table or named window and to also mean an event.
When the engine performs statement processing it may use event indexes to find correlated rows efficiently.
The purpose of event indexes is to enable:
Efficient evaluation of subqueries.
Efficient evaluation of joins.
Efficient evaluation of on-action statements.
Efficient evaluation of fire-and-forget queries.
Event index building is a result of the engine analyzing the where-clause correlation criteria for joins (on-clause for outer joins), subqueries, on-action and fire-and-forget queries.
It is done automatically by the engine. You may utilize the create index clause to explicitly index named windows and tables. You may utilize query planner hints to influence index building, use and sharing.